
Vielleicht hast du den Begriff “Crawling” schon einmal gehört, aber weißt nicht genau, was dahintersteckt? Dann bist du hier genau richtig!
In unserem Blogbeitrag rund ums Crawling erfährst du alles was du darüber wissen musst. Du hast gerade keine Lust zu lesen? Kein Problem, sieh dir einfach unser Video zum Thema “Crawling” auf YouTube an.
💡Was ist Crawling überhaupt?
Stell dir Crawling als eine Art “Internet-Detektivarbeit” vor. Hierbei durchsucht ein Webcrawler das Internet, um neue oder aktualisierte Seiten zu entdecken und diese anschließend zu indexieren. Der wohl bekannteste Crawler kommt von Google und heißt “GoogleBot”. Falls du es noch nicht wusstest, Webcrawler werden auch als “Spider” 🕷️ bezeichnet.
💡Wie funktioniert das Crawling?
Ein Webcrawler entdeckt neue und aktualisierte Seiten indem er den Links auf deiner Webseite folgt, oder durch die Sitemap.xml navigiert. Wir haben dir den Prozess bildlich dargestellt:
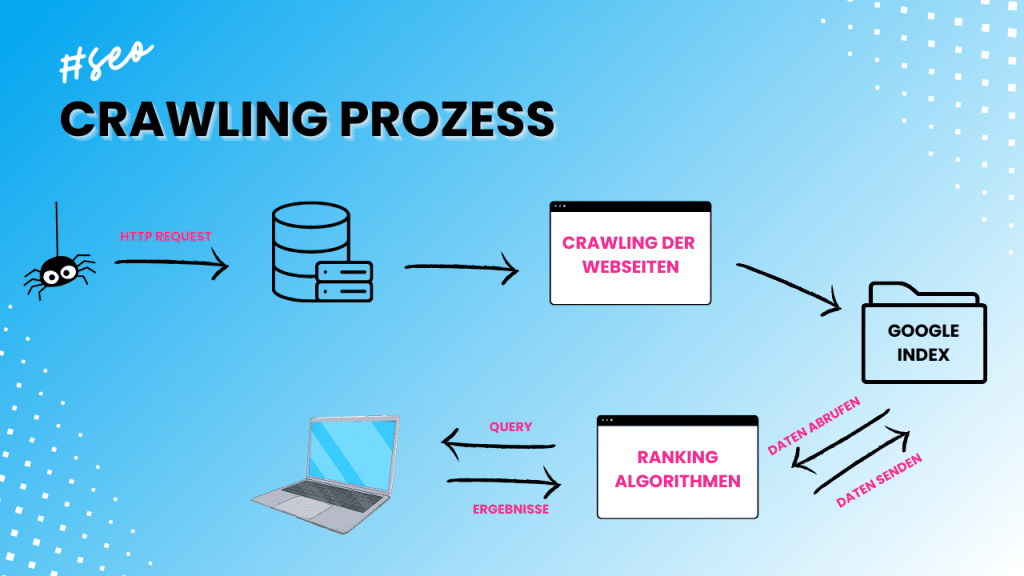
- Der Crawler (Beispiel: GoogleBot) sendet eine HTTP-Anfrage an den Server deiner Webseite.
- Er lädt den HTML Code deiner Website herunter.
- Als nächstes wird dein HTML Code bzw. der Inhalt analysiert und es werden Links zu anderen Seiten extrahiert.
- Diese neu gefundenen Links werden in eine Crawling-Warteschlange eingefügt und anschließend der Reihe nach gecrawlt.
- Nachdem das Crawling abgeschlossen wurde, kommt die Seite in den Google-Index.
- Wenn du eine Suchanfrage an Google stellst, wird mit Hilfe der Ranking-Algorithmen nach passenden Websites im Google Index gesucht.
- Sobald Google eine Auswahl gefunden hat, werden die Daten wieder zurück an die Google Algorithmen gesendet. Diese entscheiden, in welcher Reihenfolge dir die Suchergebnisse angezeigt werden.
💡Was ist ein Crawling Budget?
Das Crawling Budget ist quasi die Tagesration an Seiten, die der Webcrawler auf deiner Website in einem bestimmten Zeitraum besucht. Jede Webseite hat ein zugewiesenes Crawling Budget, welches von Google festgelegt wird. Du fragst dich, wo du das einsehen kannst?
Logge dich einfach in deinen Google Search Console Account ein und navigiere zu ▶ Einstellungen und danach zu den ▶ Crawling Statistiken. Tada! 🥳 Da ist es auch schon.
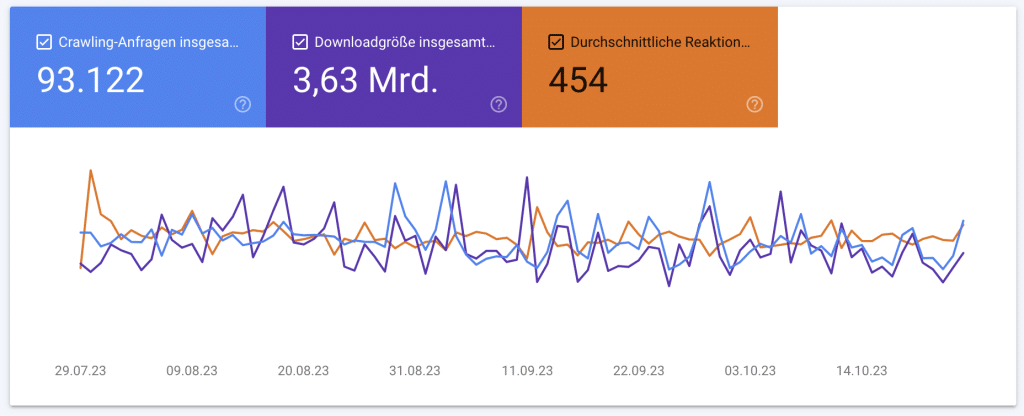
Bei den Crawling Statistiken findest du folgende Daten:
- Crawling Anfragen » blau dargestellt: Das ist die Anzahl der Crawling Anfragen, die Google an deine Website stellt. Hier gilt: Je mehr gecrawlt wird, desto besser!
- Downloadgröße » violett dargestellt: Du siehst hier die Größe aller Dateien und Ressourcen, die heruntergeladen worden sind. Hier gilt: je kleiner, desto besser! Wenn Google deine Inhalte schnell downloaden kann, können auch mehr Seiten gecrawlt werden.
- Reaktionszeit » orange dargestellt: Das ist die durchschnittliche Seitenantwortzeit für die Crawling Anfragen. Auch da gilt: je kleiner, desto besser! Denn je schneller deine Seiten reagieren, desto mehr Seiten können gecrawlt werden.
Noch mehr Infos über den Crawling Vorgang
Weiter unten in den Crawling Statistiken findest du noch weitere Aufschlüsselungen der Crawling-Anfragen.
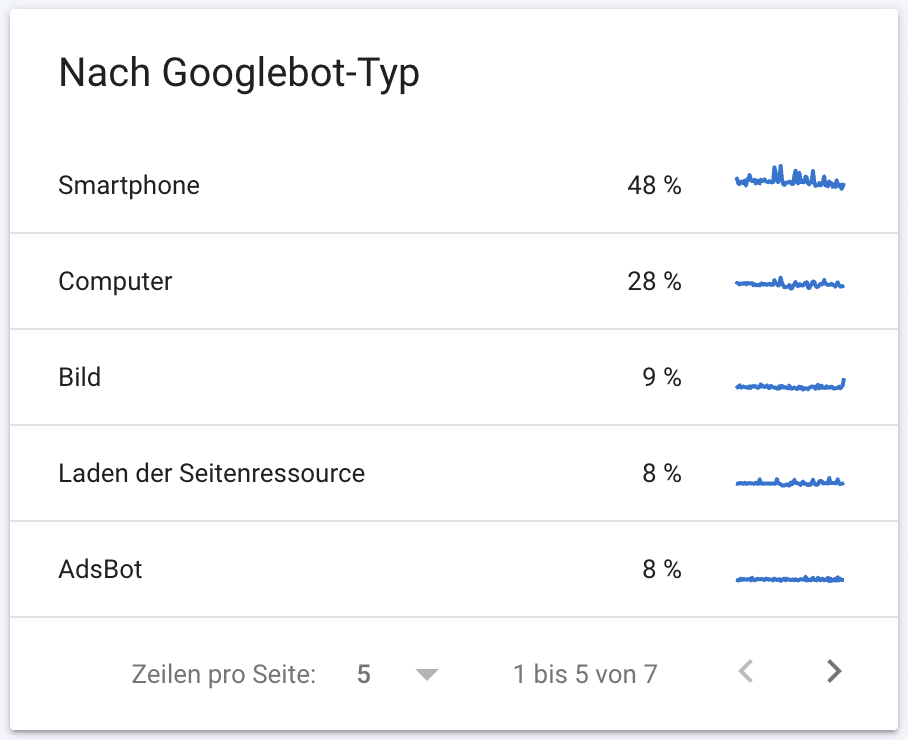
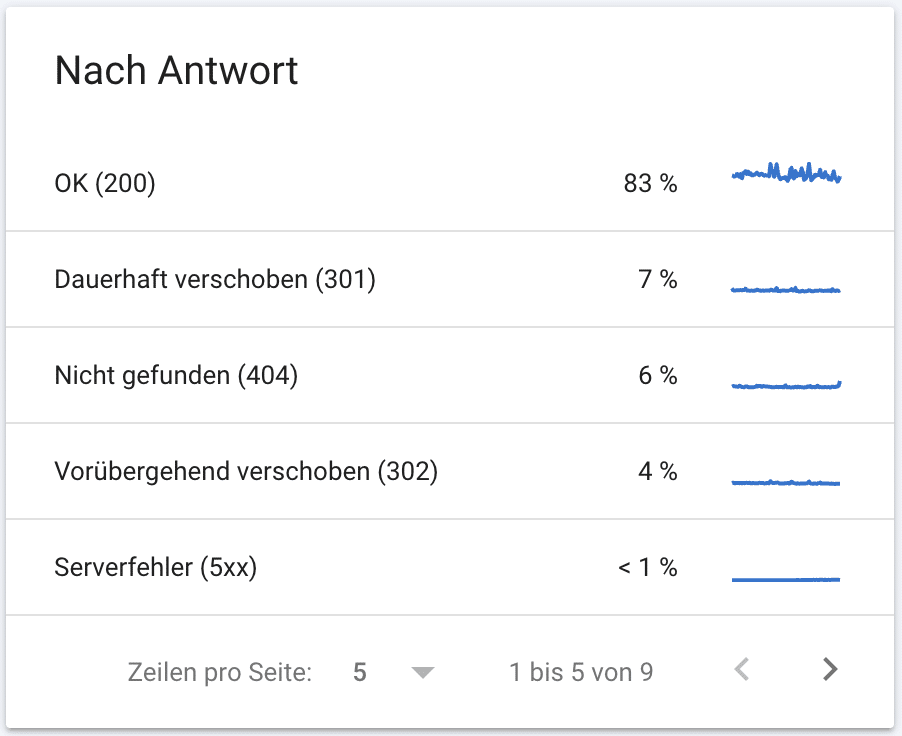
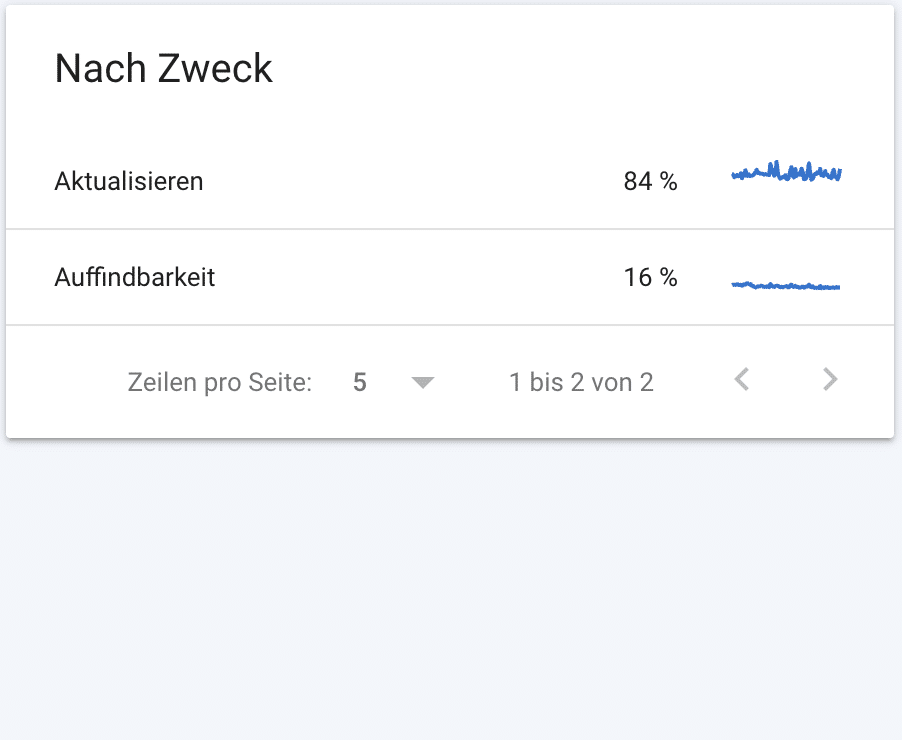
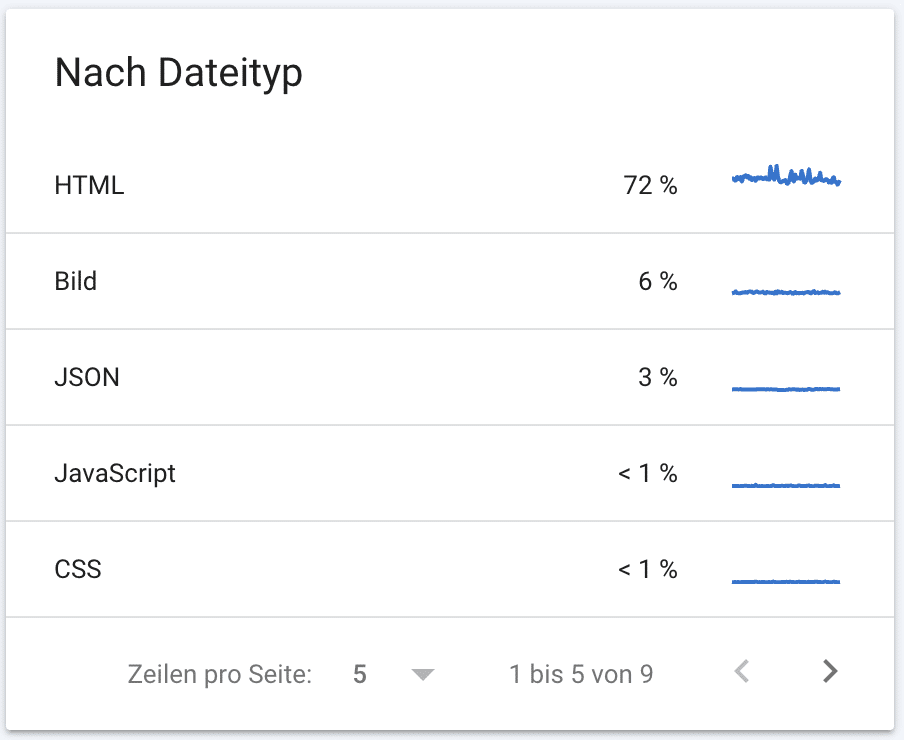
- Du siehst die Crawling-Anfragen nach Status Codes geordnet.
- Du kannst sehen, welche Dateitypen Google gecrawlt hat.
- Du siehst den Zweck des Crawlings. Wie viele Seiten hat Google aktualisiert und wie viele wurden neu gefunden?
- Im letzten Feld siehst du, mit welchen GoogleBot-Typen Google deine Website crawlt.
💡Was beeinflusst dein Crawling Budget?
Es gibt einige Schlüsselfaktoren, die beeinflussen, wie oft und wie gründlich Google deine Website crawlt:
- Dein Webserver: Websites mit schneller Serverleistung haben in der Regel ein größeres Crawling Budget.
- Serverfehler: Je weniger Serverfehler während des Crawlings auftreten, desto höher ist deine Crawling Frequenz.
- Seitenqualität: Seiten ohne Mehrwert wirken sich negativ auf das Crawling Budget aus. Du solltest daher darauf achten, keinen Duplicate Content und keine Spam Seiten zu produzieren.
Ich hoffe, du hast jetzt einen besseren Überblick über das Thema “Crawling”. Wenn du mehr über die Optimierung deines Crawling Budgets erfahren möchtest, sei auf unseren Folgebeitrag zum Thema “robots.txt und sitemap.xml” gespannt. Dieser wird in Kürze veröffentlicht.
Du kannst nicht genug von uns bekommen? 😉
Dir gefällt unser SEO Basics Beitrag zum Thema “Crawling”? Du möchtest mehr über unsere SEO Agenturleistungen erfahren? Dann schau in unserem SEO Bereich vorbei! Wir helfen dir beim Audit deiner Website, deinem Relaunch, beim Erstellen von Content oder unterstützen dich mit einer monatlichen SEO Betreuung.




